
Trending

Editor’s note: Today, we’re sharing an excerpt from our latest issue of Disruption Investor. It’s a must-read for anyone who’s invested in—or who plans to invest in—artificial intelligence (AI) stocks...
From the October issue of Disruption Investor:
Imagine if your iPhone came with a "think hard" button.
Press it, and suddenly your smartphone becomes as smart as a room full of PhDs. It could solve physics puzzles and decode biology riddles that’d stump most experts.
OpenAI’s new model o1 comes equipped with this superpower. In short, the more it “thinks,” the smarter it gets. And not just a little smarter, A LOT smarter.
GPT-4 can only solve 13% of Math Olympiad problems. o1 nails 83% of them.
Don’t fight the law.
I first introduced you to the new AI “law” back in 2020. It states: “With every 10X increase in the amount of data you feed into an AI model, its quality doubles.”
To boost performance, AI companies must use ever-greater amounts of computing power. Over the past decade, the “compute” needed to train the latest AI models has surged 1,018,766,656%!
It’s hard to wrap your head around “1 billion percent.” It’s the equivalent of turning $1 into $10 million. That's the kind of exponential growth AI has achieved.
“Scaling laws” are the cheat code for making AI smarter. It's why GPT-4 runs circles around GPT-3.
Financial news outlet Bloomberg created “BloombergGPT” to gain an edge in analysis and forecasting. It fed the model every scrap of data Bloomberg had gathered over 40+ years.
GPT-4, which wasn’t specifically trained for finance, smoked it in tasks like figuring out the sentiment of earnings calls. It didn’t matter how much high-quality, “proprietary” data Bloomberg had because GPT-4 was 100X bigger.
With AI, bigger is better.
We knew “scaling laws” apply to training AI models—all the work that goes on behind the scenes before the AI is released into the wild. What we discovered with o1 is this law also applies to “inference,” too.
Before: The more data you feed AI, the better the answers (training).
Now: The harder AI thinks, the better the answers (inference).
Inference is a $10 word. In plain English, when you ask ChatGPT a question and it answers, that’s inference.
The $10 word worth billions…
When AI companies discovered scaling laws, they hoovered up every crumb of data they could find and used it to train their models.
We know what happened next. Spending on AI infrastructure went gangbusters.
The original ChatGPT cost roughly $10 million to train. GPT-4 cost $100 million. The next generation of models will likely cost a billion dollars or more to train.
Meanwhile, Nvidia’s (NVDA) AI revenues have surged 3,600%.
So far, roughly 90% of AI spending has gone toward training the models. OpenAI’s new model marks a turning point. The most important investment conclusion from o1 is spending on inference is set to surge.
Our research suggests we could easily see 100X growth within the next five years. A truly massive uptick in processing power is needed to run these beefed-up AI models.
Okay Stephen, what does that mean for my portfolio?
AI spending is about to go through the roof (again). The top AI firms are already putting the wheels in motion.
Until a month ago, the largest cluster of graphics processing units (GPUs) in the world was 32,000. That’s 32,000 Nvidia chips all linked together to form one big AI brain.
In just the past few weeks, Elon Musk’s xAI startup built a cluster of 100,000 GPUs…
Meta Platforms (META) announced it’s putting the final touches on its own 100,000-strong army of Nvidia chips to train its next AI model. Price tag: $3 billion.
And cloud giant Oracle (ORCL) revealed it’s crafting a data center packed with 130,000 of Nvidia’s new Blackwell GPUs!
Oracle founder Larry Ellison recently said:
I went to dinner with Elon Musk and Jensen Huang, and I would describe the dinner as me and Elon begging Jensen for GPUs. Please take our money. No, take more of it. We need you to take more of our money, please.
The CEOs of the most powerful, richest companies in history are telling you AI spending is only going one way: UP.
We want to own businesses drinking from this firehose of cash.
AI everywhere, all at once.
As AI becomes widespread, the amount of “compute” we need will continue to surge. Data from top venture capital firm Coatue suggests 100 million people using ChatGPT consumes 4X more compute (per day!) than what it took to train the model:
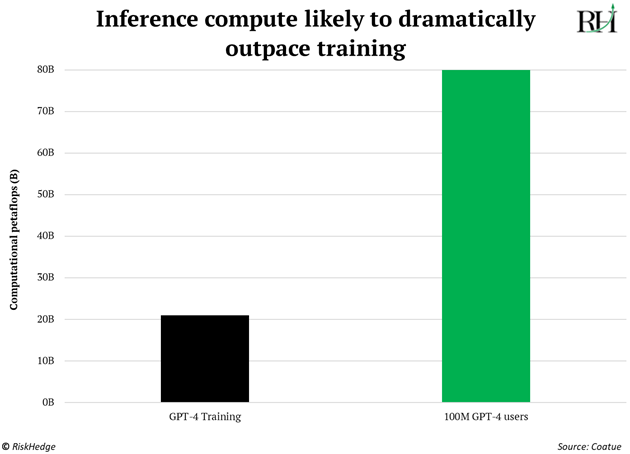
The models will be trained in giant data centers packed to the rafters with powerful GPUs. And we’ll all have personalized AI assistants running on our iPhones that know us better than we know ourselves.
Investors calling AI a bubble are making a mistake. AI was a bubble. Many folks don’t know the first AI research paper was published in 1943!
Vladimir Lenin once said, “There are decades where nothing happens, and there are weeks where decades happen.”
We've had eight decades where nothing happened. Understand we’re now in the weeks where decades happen.
Tech adoption is moving faster than ever. OpenAI recently announced 200 million people now use ChatGPT at least once a week. Nobody had heard of ChatGPT two years ago!
Compare that to the first steam engine, which was designed in the early 1700s. It took 150 years for steam power to become broadly adopted in factories and trains.
We’re still in the early stages of the AI opportunity.
Our job is to invest in the great businesses riding the AI wave to unprecedented heights.
PS: Most people assume investing in Nvidia is the best way to capitalize on the AI megatrend. But it’s not the only winner here.
More “inference” means a complete overhaul of AI data centers. And more money going toward companies that make cooling fans… storage disks… memory chips… and so on.
To stay up to date on the top AI stocks not named Nvidia, sign up to The Jolt today.
Related: The GOAT Just Called the Election