
Trending

I spent the first week of 2021 in the same way that I have spent the first week of every year since 1995, collecting data on publicly traded companies and analyzing how they navigated the cross currents of the prior year, both in operating and market value terms. I knew that this year would be more challenging than most other years, for two reasons.
The first was that the shut down of the global economy, initiated by the spreading of COVID early last year, had significant effects on the operations of companies in different sectors, and across the world.
The second was that, starting mid-year in 2020, equity markets and the real economy moved in different directions, with the former rising on the expectations a post-virus future, and the latter languishing, as most of the world continued to operate with significant constraints.
In this post, I will start with a rationalization of why I do this data analysis every year, follow up with a description (geographic and sector) of the overall universe of companies that are in my analysis, list out the variables that I estimate and report, and conclude with a short caveat about 2020 data.
Data: A Pragmatist View
We live in the age of data worship, where investors, analysts and businesses all seem to have bought into the idea that big data has answers for every question and that collecting the data (or paying for it) will create positive payoffs. I am a skeptic and I have noted that to make money on big data, two conditions have to be met:
- If everyone has it, no one does: I believe that if everyone has a resource or easy access to that resource, it is difficult to make money off that resource. Applying that concept to data, the most valuable data is unique and exclusively available to its owner, and the further away you get from exclusivity, the less valuable data becomes.
- Data is not dollars: Data is valuable only if it can be converted into a product or service, or improvements thereof, allowing a company to capture higher earnings and cash flows from those actions. Data that is interesting but that cannot be easily monetized through products or services is not as valuable.
All of the data that I use in my data analysis is in the public domain, and while I am lucky enough to have access to large (and expensive) databases like Bloomberg and S&P, there are tens of thousands of investors who have similar access. Put simply, I possess no exclusivity here, and staying consistent with my thesis, I don't expect to expect to make money by investing based upon this data. So, why bother? I believe that there are four purposes that are served:
- Gain perspective: One of the challenges of being a business or an investor is developing and maintaining perspective, i.e., a big picture view of what comprises normal, high or low. Consider, for instance, an investor who picks stocks based upon price to book ratios, who finds a stock trading at a price to book ratio of 1.5. To make a judgment on whether that stock is cheap or expensive, she would need to know what the distribution of price to book ratios is for companies in the sector that the company operates in, and perhaps in the market in which it is traded.
- Clear tunnel vision: Investors are creatures of habit, staying in their preferred markets, and often within those markets, in their favored sectors. Equity research analysts are even more focused on handfuls of companies in their assigned industries. So what? By focusing so much attention on a small subset of companies, you risk developing tunnel vision, especially when doing peer group comparisons. Thus, an analyst who follows young technology companies may decide that paying ten times revenues for a company is a bargain, if all of the companies that he tracks trade at multiples greater than ten times revenues. Nothing is lost, and a great deal is gained, by stepping back from your corner of the market and looking at how stocks are priced across industries and markets.
- Expose BS: I know that everyone is entitled to their opinions, but they are not entitled to their facts. I am tired of market experts and analysts who make assertions, often based upon anecdotal evidence and plainly untrue, to advance a thesis or agenda. Are US companies more levered than they were a decade ago? Do US companies pay less in taxes than companies in other parts of the world? Are companies that buy back stocks more financially fragile than companies that do not? These are questions that beg to be addressed with data, not emotions or opinions. (I know.. I know... You would like those answers now, but stay tuned to the rest of my data updates and the data will speak for itself.)
- Challenge rules of thumb and conventional wisdom: Investing has always had rules of thumb on how and when to invest, ranging from using historical PE or CAPE ratios to decide if markets are over valued, to simplistic rules (eg. buy stocks that trade at less than book value or trade at PEG ratios less than one) for individual stocks. It is very likely that these rules of thumb were developed from data and observation, but at a different point in time. As markets and companies have moved on, many of them no longer work, but investors continue to use them. To illustrate, consider a practice in valuation, where analysts are trained to add a small cap premium to discount rates for smaller companies, on the intuition that they are riskier than larger companies. The small cap premium was uncovered in the the early 1980s, when researchers found that small cap stocks in the US earned significantly higher returns than large cap stocks, based upon data from 1926 to 1980. In the decades since, the small cap premium has disappeared in returns, but inertia and laziness have kept the practice of adding small cap premium alive.
In closing, I also want to dispense with the notion that data is objective and that numbers-focused people have no bias. If you have a bias or a preconception, it is amazing how quickly you can bend the data to reflect that bias or preconception. As an exercise, take a look at my updated industry averages for taxes paid by US companies in 2021. From past experience, I predict that numbers in this table will be quoted by journalists, economists and even politicians, with very different agendas, but the tax rate measure (since I report several different measures) that they quote will reflect their biases. Put simply, if you find my data quoted elsewhere, I would suggest that you visit the source and make your own judgments.
The Sample
The focus in markets is often on subsets of firms, usually with good reason. In general, larger firms (especially in market value terms) get more attention that smaller ones, because their movements in their value are more consequential for more investors Also, publicly traded firms generally garner more attention than privately owned businesses, partly because they are larger, but also because there are is more information disclosed and investment opportunity with the former. Finally, fair or not, companies in developed and more liquid markets are in the spotlight more than their counterparts in emerging markets. That said, focusing on just large or developed market companies can create biased samples and skew assessments about market and operating performance. It is to avoid this that I started by looking at all publicly traded companies that were traded on January 1, 2021, and arrived at a sample of 46,579 firms, spread across 136 countries.

While the universe of companies is diverse, with approximately half of all firms from emerging markets, it is more concentrated in market capitalization, with the US accounting for 40% of global market capitalization at the start of the year. Using the S&P categorization of global companies into sectors, the data universe looks as follows:
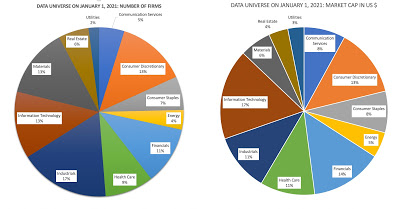
It should come as no surprise, especially given their performance over the last year, that the technology sector is the largest in terms of market capitalization. While some of the companies in this data trace their existence back decades, there is a healthy proportion of younger companies, many in emerging markets and new industries.

Finally, it is worth noting that, notwithstanding the travails of last year, the number of firms in the data universe increased from 44,394 firms at the start of 2020 to 46,579 firms, a 4.9% increase over the year, as new listings outnumbered companies that defaulted during the course of the year.
If there is a hole in my sample, it is the absence of privately owned businesses. One reason is that these businesses are not only not required to publicly disclose their financial details in most parts of the world, but often follow more malleable accounting standards, making the data less reliable and comparable. The other is that even in those parts of the world, where private company information is available, the data is limited and market price data is missing (since the companies are not traded). That said, it does mean that any broad conclusions (about profitability and revenues) that emerge from my data apply to public companies, and it may be dangerous to extrapolate to private businesses, especially in a year like 2020 where private businesses could have been affected more adversely by COVID shutdowns than public companies.
The Data
As more data has become publicly available, and access to the data becomes easier, the challenge that we face in investing and valuation is that we often have too much data, and information overload is a clear and present danger. In this section, I will list the data that I estimate and report, as well as explain how I consolidate company-level data into more usable group statistics.
General Details
While there are advantages to looking across all firms, small and large, listed anywhere in the world, there are challenges that come from casting such a wide net. I have tried my best to keep them from overwhelming the analysis, and in the interests of openness, here are some of the details:
- Currency: One of the challenges of dealing with a global sample is that you are working with accounting and market numbers quoted in multiple currencies, and since you cannot aggregate or average across them, I will employ two techniques. First, all value numbers (like market capitalization, debt or revenues) that I aggregate or average will be converted into US dollars to ensure currency consistency. Second, most of the numbers that I report will be ratios, where the currencies are no longer an issue; a PE ratio for a Turkish company, with market cap and earnings denominated in Turkish Lira, can be compared to the PE ratio for a US company, with market cap and earnings denominated in US $. It is true that the Turkish company will face more risk because of its location, but that is an issue separate from currency.
- Missing Data: Information disclosure requirements vary across the world, and there are some data items that are available for some companies or some markets, and not for others. Rather than remove all firms with missing data, which will eliminate a large portion of my sample, I keep the firms in the sample and report only the variable/metric that is affected by the missing item as "NA". For instance, I have always computed the present value of lease commitments in future years and treated that value as debt, a practice that IFRS and GAAP have adopted in 2019, but that computation requires explicit disclosures of lease commitments in future years. That is standard practice in the United States, but not in many emerging markets, but rather than not do the computation for all companies or remove all companies with missing lease commitments, I compute lease debt for those companies that report commitments and report it as zero for those companies that do not, an imperfect solution but the least imperfect of the many choices.
- Accounting Differences: In addition to disclosure differences, there are also accounting differences in revenue recognition, expensing rules, depreciation methods and other details across markets. I work with the publicly available data, recognizing that net income for a Japanese company may be measured differently than earnings for an Indian company, and accept that this may skew the results. However, it is worth noting that accounting rules around the world have converged over the last four decades, and they share a lot more in common than they have as differences.
- Source Reliability and Errors: I obtain my raw data from S&P, Bloomberg and others, and I am grateful that I can do that, because I could never hand collect and input data on 40,000+ companies. They, in turn, obtain the data from computerized databases in different markets that collect public filings, and at every stage in this process, there is the possibility of errors. I do run some simple error checks to eliminate obvious mistakes, but I am sure that there are others that I miss. My defense is that, unless the mistake is on a very large scale, the impact it has on my group statistics is small, simply because of my sample size. In addition, there is also the possibility of accounting fraud in some companies, and there is little or nothing that can be done about them.
I am not trying to pass the buck or evade responsibility for any mistakes that persist but if you do find odd looking values for some variables that I report, especially for small samples, take them with a grain of salt.
Macro Data
I do not report much macroeconomic data for two reasons. The first is that I do not have a macro focus, and my interests in macro variables occur only in the context of corporate finance or valuation issues. The second is that there are great (and free) sources for macro economic data, ranging from the Federal Reserve (FRED) to the World Bank and I don’t see the point of replicating something that they already do well. The macro variables that I track on my site relate to the price of risk, a key input into valuation, in both equity and debt markets:
- US Equity Risk Premiums: The equity risk premium is the price of risk in equity markets. In my view, it is the most comprehensive measure (much more so than PE ratios or other pricing multiples) of how stocks are being priced, with a higher (lower) equity risk premium correlating with lower (higher) stock prices. The conventional approach to measuring this premium is looking at past returns on stocks and treasuries (or something close to riskfree) and measuring the difference in historical returns and I report the updated levels (through 2020) for historical premiums for stocks over treasuries in this dataset. I have argued that this approach is both backward looking and static, and have computed and reported forward-looking and dynamic equity risk premiums, based upon current stock price levels and expected future cash flows; you can find both the current level and past values in this dataset.
- Country Risk Premiums: In a world where both investing and business is globalized, we need equity risk premiums for markets around the world, not only to value companies listed in those markets, but also to value companies that have operations in those countries. I will not delve into the details here, but I use the same approach that I have used for the last 30 years to estimate the additional risk premiums that I would charge for investing in other markets to get equity risk premiums for almost every country in the world in this dataset.
- Bond Default Spreads: The bond default spread is the price of risk in corporate bond (lending) markets, and as with the equity risk premium, higher (lower) spreads go with lower (higher) corporate bond prices. In the same dataset where I compute historical equity risk premiums, I report historical returns on corporate bonds in two ratings classes (Moody’s Aaa and Baa ratings). I also report estimates of the default spreads based upon current yields on bonds in different ratings classes and the current riskfree rate.
I am not an interest rate prognosticator, but since today’s low rate environment seems to have made everyone a forecaster of interest rates, I do compute an intrinsic version of the US treasury rate and compare it to current levels in this dataset.
Micro Data
The focus of my data collection is understanding how companies are operating and how investors are pricing them. That said, you will not find individual company data on my site for two reasons. The first is that I bear a responsibility (ethical and legal) to my raw data providers to not undercut their businesses by giving away that data for free. The second is that you don’t need my site or any public site to get data on an individual company; if you want to get data on a company, there is no better way to do it than go to the source, which is the company’s annual or quarterly filings. To understand and use the data, here are some specifics that you may (or may not) find useful:
- Industry: Data can be consolidated by geography, industry or company size, and I use all three, to some extent or the other. My primary consolidation is by industry and I break down my sample of 46,579 firms into 94 industry groupings. To make this classification, I start with the industry classifications that are in my raw data, but create my own industry groups, again to prevent stepping on the toes of my data providers. I know that this description is opaque, but the best way to understand my industry groups is to go to this dataset, where I report the companies that I include in each industry.
- Geography: There is one dataset where I look at companies broken down by country, and I report a number of different statistics for 136 countries. I would caution you to take this data with a grain of salt, since there are only a handful of listings in some country. I do report much more data for a broader geographical classification, where I classify firms into six broad geographical groupings: Note that while emerging markets is a very large and diverse group, I do report statistics for India and China, two of the bigger components, separately.
- Averaging: I hope it does not sound patronizing, but I want to explain how I compute group values (averages), because it is not as obvious as it sounds. To illustrate why, consider the challenge of computing the PE ratio for companies in the software industry. You could compute the PE ratio for each company in the group and take a simple average, but that approach has two problems. First, it weights small firms as much as large firms, and outliers can cause the average to take on outlandish values. Second, it eliminates firms that have negative earnings (and thus have no PE ratios) from the sample, potentially creating biased samples. Using a weighted average PE ratio can counter the first problem and using a median can reduce the outlier effect, but neither approach can deal with the second problem (of sample bias). For most of my industry averaging, I use an aggregation approach, where I compute ratios using aggregated values; to compute the PE ratio for chemical companies, I add up the market capitalizations of all chemical companies and divide that number by the aggregate net income of all chemical companies (including money losers). This ensures that (a) all companies are counted, (b) the computed number is weighted since larger companies contribute more to the aggregate and (c) the risk of outliers is reduced, since it is less likely to occur in a large sample than for an individual firm.
- Current data: The focus of this data update is to report on how companies did in 2020, rather than to provide historical time series. Since I am updating the data in early January 2021, and the complete numbers for 2020 will not be available until March or April at the earliest, I will be using the trailing twelve month numbers for operating variables (like revenues and operating income) to compute ratios. For accounting numbers, that will effectively be the twelve months through September 30, 2020, that will be captured in the data. This practice of focusing on current data can cause the computed numbers to be volatile, but I do have the archived data going back in time (more than 20 years in the US, less for other parts of the world) at this link.
Variables
I confess that I have a primary constituency when I think of the variables that I would like to estimate, and that (selfishly) is me. Since my interests lie in corporate finance and valuation, the statistics that I compute are numbers that I will find useful when doing a corporate financial analysis or valuation of a company. Since I compute and report on dozens of variables, the best way of summarizing what you will find on my website in the following picture:

With each variable, I report the industry averages by geography. With cost of capital, for instance, I report the cost of capital by industry for the US at this link, and datasets that can be downloaded by geography: Europe, Emerging Markets (China and India), Australia, NZ & Canada, Japan & Global).
COVID Effects
I would normally not belabor the fact that my data is focused on the most recent year, but 2020 was an unusual year. Starting in February and extending for most of the rest of the year, the economic shutdown created turmoil in both financial markets an the real economy. While markets, for the most part, have recovered strongly, large segments of the real economy have not. Consequently, there are a couple of considerations if you use this year’s numbers:
1. COVID effects: To capture how COVID has played out in different sectors and geographies, I computed the changes in aggregate market capitalization during 2020 broken down by sub periods (1/1/20 - 2/14, 2/14- 3/20, 3/20 - 9/1 and 9/1 - 12/31/20), reflecting the ups and downs in the overall market. I also looked at the change in revenues and operating income over the last twelve months (October 2019 - September 2020) compared to revenues in the year prior (October 2018 - September 2019). Since the worst effects of the crises were in the second and third quarters of 2020, this comparison should provide insight into how much damage was wrought by the viral shutdown. Just as a preview of how consequential the year was for stock prices, take a look at the median percentage change in market capitalization in the table below:

I will come write more extensively about the COVID effects in a future post, but you can see the data for US companies, broken down by industry, by clicking here, ands you can also download the data for other geographies here: Europe, Emerging Markets (China and India), Australia, NZ & Canada, Japan & Global.
2. Operating metrics: My computations for operating margins and accounting returns (returns on equity and capital) reflect the COVID effect on earnings in 2020, and not surprisingly, you will see that their values are much lower for the most damaged sectors (restaurants, airlines) than in prior years. If you are comparing across companies in these sectors, that may not be an issue, but if you are valuing companies and want to find a target value for margins or accounting returns, you will be better served using my archived values for these variables from 2019.
3. Pricing metrics: I compute and report a range of pricing multiples from PE ratios to Enterprise Value (EV) to sales ratios, but as with the operating metrics, COVID has left its imprint on the numbers this year. As market capitalizations have quickly retraced their losses, but operating variables have not, the multiples reflect that disconnect. They are either not meaningful in some sectors, which are reporting aggregated losses, or at elevated levels in others (where the collective earnings are down significantly, but market values are not). Again, while this should not be an issue with cross company comparisons, there are two cautionary notes. The first is that investors who come in with strong preconceptions of what comprises cheap or expensive in pricing ratio terms or historic norms will find that everything looks exorbitantly priced. The other is that you will lose large segments of your peer groups if you stick with multiples like PE ratios for comparisons, since so many companies will be money losing.
Access and Use of Data
I know that the numbers (in terms of companies and variables) makes this data update sound like daunting work, but I will make a confession. I enjoy the process, even including the messy details, and it prepares me for the year to come. In fact, the time that this aggregated data saves me through the year, when I value and analyze companies, represents a huge multiple of the time I spend putting it together. Put simply, if you are tempted to anoint me for sainthood for sharing my data, you are overreaching because I would do it anyway, and sharing it costs nothing, while potentially benefiting you. If you decide to use the data, here are some things that I hope you will consider:
- Data access: The data is accessible on my website, if you click on data. The data for 2020 is available under current data, and data from previous years under archived data. If you do click on current data, you will see the data classified into groupings based upon how I see the world (corporate governance, risk, investment returns, debt, dividends and pricing). You can see the data online for US companies by clicking on the links next to the data item, but I would strongly recommend that you download the excel spreadsheets that contain the data instead. Not only will this let you access data for other geographical regions, but each excel spreadsheet includes descriptions of the variables reported in that dataset and many include short YouTube videos explaining the data.
- Data Use: I know that those who download my data use it in many different contexts. If you use it at their jobs as corporate finance or equity analysts, I am glad to take some of that burden off you, and I hope that you find more enjoyable uses for the time you save. If you use my data to buttress an argument or debunk someone else’s, I wish you the best, as long as you don’t make it personal. If you use is it to back your case in legal settings, go ahead, but please do not involve me formally. I believe that courts are a graveyard for good valuation practices and while I do not begrudge you, I have no interest in playing that game.
- Data Questions: If you have a question about how a variable is computed, please check the website first, since the question has probably been answered already, but if you cannot find that answer, you know how to find me, and I will try to address your issues. As I mentioned earlier, the excel spreadsheets that contain the data include the descriptions of how I compute the variables.
- Suggestions and Complaints: Before you send off angry or impassioned emails to my team, about my data, you should know that this team has only one member and it is me. I am not a full time data service, and I cannot provide customized data solutions. If you find a mistake in a computation or a typo, please do let me know, and I will fix the error, perhaps not as quickly as you would like me to, but I will.
In sum, I hope you find the data that I provide useful. In the next month, I will add about a dozen posts on what I see in the data, but I will do so with the recognition that change is the only constant and that assuming that things always revert back to historic norms is not an investment philosophy.